为推进专利开放许可工作,提升专利转化水平,本期发布5项专利,具体信息如下:

本发明公开了一种云数据中心里基于共享内存页面的虚拟机整合方法,当云数据中心里热迁移虚拟机时,首先按物理资源可用量降序排列物理机,然后每次从待选虚拟机中挑选一定数量的包含最小内存页面数量的虚拟机装载至物理机上,直到所有虚拟机都被整合至物理机中。本发明在整合虚拟机至物理机时利用了虚拟机内存内容之间的相似性,在使用了较少数量的物理机同时,也大幅度减少了热迁移虚拟机时所需传输的内存数据量,从而提高云数据中心里物理资源的利用率。

本发明公开了一种云数据中心里基于共享内存页面的虚拟机选择与放置方法,当云数据中心里热迁移虚拟机时,首先按CPU资源可用量降序排列未过载的物理机,然后在考虑CPU资源使用的情况下每次从过载物理机中挑选出需要传输内存页面数尽可能少的虚拟机来依次迁移至未过载的物理机,直到所有物理机都处于未过载的状态。本发明将虚拟机挑选与虚拟机放置过程同时完成,在减少虚拟机热迁移过程中传输流量的同时,也减少了能量消耗,从而提高云数据中心物理计算资源的利用率。

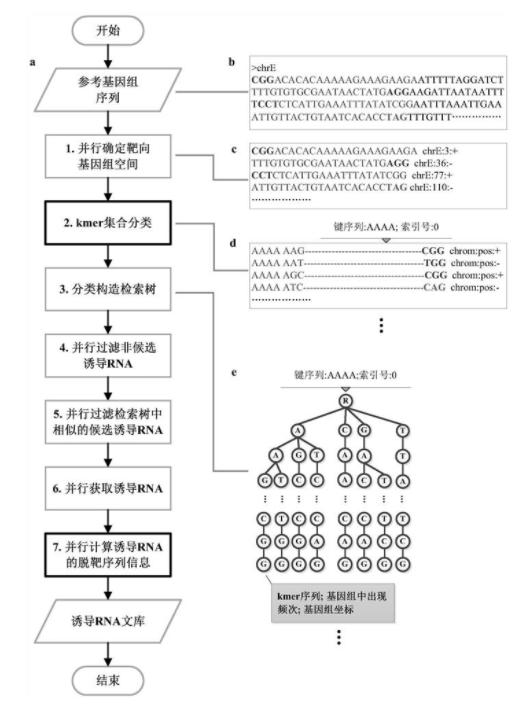
本发明公开了一种CRISPR诱导RNA文库设计方法,包括以下步骤:步骤一、根据参考基因组生成kmer集合;步骤二、将kmer切分成kmer1和kmer2两部分,将对应的kmer1相同的kmer2分成一个类别;再将同一类别的kmer2构建到同一个检索树中,各检索树的键序列为其中kmer2对应的kmer1;步骤三、并行获取诱导RNA及其脱靶序列,该步骤中,在比对一个kmer与检索树的键序列和其中的kme2连接成的kmer时,首先将该kmer的kmer1与检索树的键序列比对,看是否满足设定条件,满足则继续比对kmer的kmer2与检索树中的kmer2。本发明提高了计算效率。

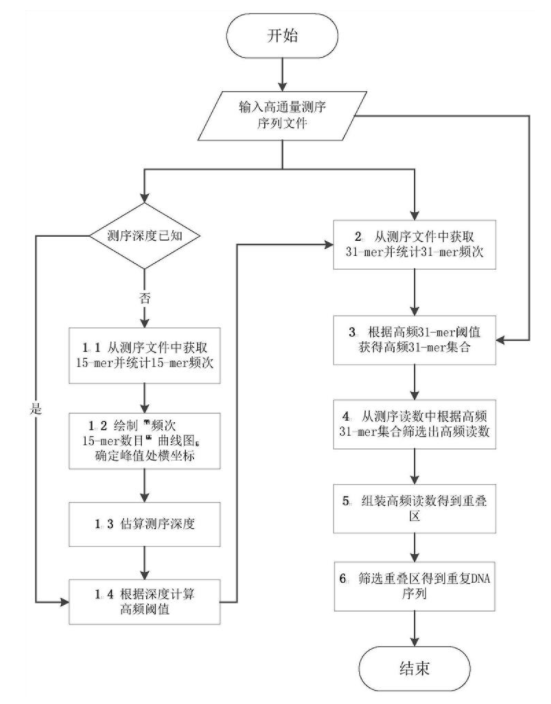
本发明公开了一种基于高通量测序读数的重复DNA序列识别方法,包括:由高通量测序的读数得到高频k-mer集合,根据高频k-mer集合对读数进行筛选,使得包含高频k-mer较多的读数保留下来,成为高频读数;使用序列组装工具组装高频读数,得到contigs序列;对contigs序列进行筛选,保留下的所有contigs序列即为重复DNA序列。本发明可以从高通量测序读数中识别重复DNA序列,而无需物种参考序列,可以适用于参考序列未知的物种的重复DNA序列识别,并且本发明是通过组装高频读数得到重复DNA序列,相对于组装高频k-mer得到重复DNA序列,提高了识别重复DNA序列的准确率。

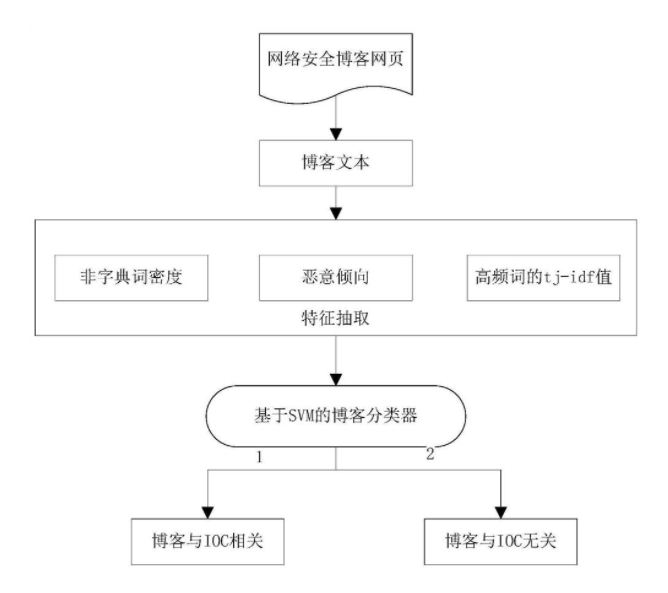
本发明公开了一种基于特征抽取的网络安全博客分类方法及系统,包括:爬取博客;计算每个博客的非字典词密度;计算每个博客的博客恶意倾向度;统计所有博客共同的高频词;计算每个博客中各个高频词的词频逆文档频率;基于博客的非字典词密度、博客恶意倾向度以及每个博客中每个高频词的词频逆文档频率,以及基于博客与IOC的相关或不相关进行编码来训练预设分类模型得到博客分类器;获取待分类博客的非字典词密度、博客恶意倾向度以及高频词的词频逆文档频率并输入至训练后的博客分类器得到表示待分类博客与IOC的相关或不相关的分类器输出值。通过上述方法实现对网络安全技术博客中与IOC相关的博客和与IOC无关的博客精确分类。